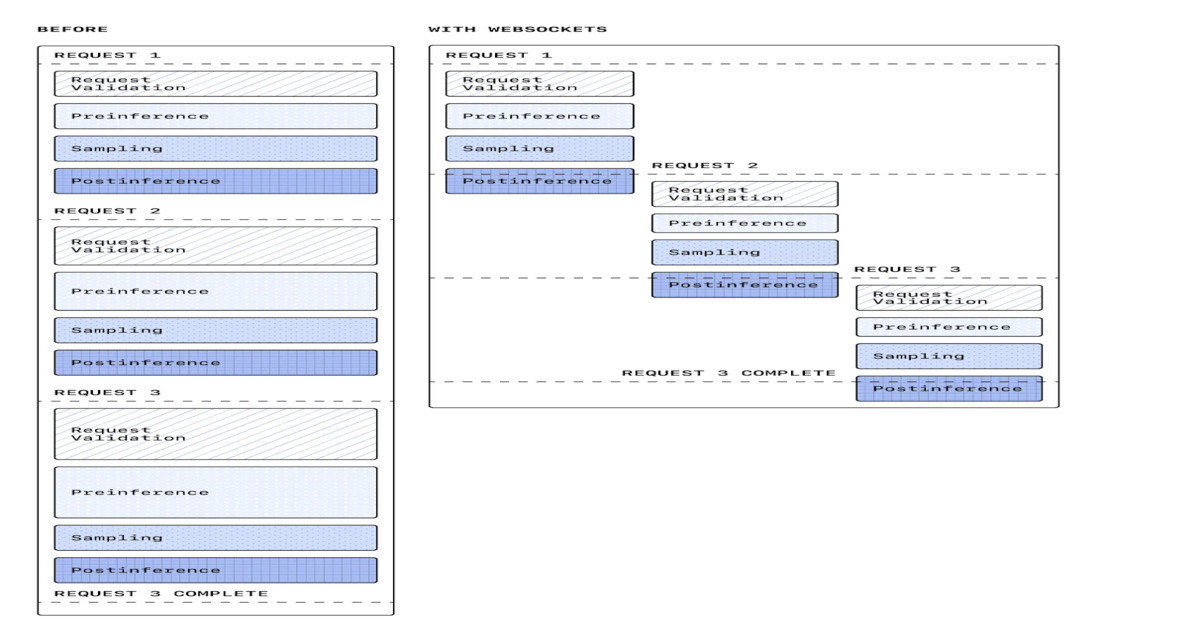
"OpenAI has introduced a WebSocket-based execution mode for its responses API to improve the performance of agentic workflows used in coding agents and real-time AI systems. The change replaces the traditional HTTP request-response pattern with a persistent, bidirectional connection between client and server, targeting latency and coordination overhead in multi-step reasoning workflows."
"The WebSocket-based execution mode uses a long-lived, bidirectional connection to enable continuous data exchange without repeated handshakes. This supports streaming responses, faster tool execution, and more efficient coordination of multi-step workflows. It aligns with event-driven design patterns in distributed systems, where maintaining state across interactions improves responsiveness and throughput."
"OpenAI reported up to 40% latency reduction in early production use, along with sustained throughput of around 1,000 transactions per second and bursts up to 4,000 TPS. These results indicate that transport-level optimizations can significantly impact end-to-end AI system performance."
OpenAI introduced a WebSocket-based execution mode for its responses API to optimize agentic workflows in coding agents and real-time AI systems. This replaces traditional HTTP request-response patterns with persistent, bidirectional connections that eliminate repeated network round-trip times. Each step in multi-step workflows—including tool calls, intermediate reasoning, and follow-up queries—previously required separate HTTP requests, creating latency bottlenecks as inference speeds improved. The WebSocket approach enables continuous data exchange without repeated handshakes, supporting streaming responses and more efficient workflow coordination. Early production results show up to 40% latency reduction, sustained throughput around 1,000 transactions per second, and burst capacity up to 4,000 TPS, demonstrating that transport-layer optimizations significantly impact overall AI system performance.
#websocket-optimization #agentic-workflows #latency-reduction #api-performance #real-time-ai-systems
Read at InfoQ
Unable to calculate read time
Collection
[
|
...
]